Visual Generation
Diffusion models, flow matching, image generation, and high-quality controllable synthesis.
I am a Ph.D. student in Computer Science at Fudan University. My research focuses on visual generative models, especially diffusion and flow-based image/video generation, human-centric video generation, and efficient generative model training and inference.
I am advised by Prof. Siyu Zhu (朱思语) and Dr. Jingdong Wang (王井东).

Research
Diffusion models, flow matching, image generation, and high-quality controllable synthesis.
Large-scale video datasets, motion-aware filtering, portrait animation, and talking video generation.
Pyramidal patchification, accelerated inference, and reducing train-test discrepancy in generative models.
Selected Work
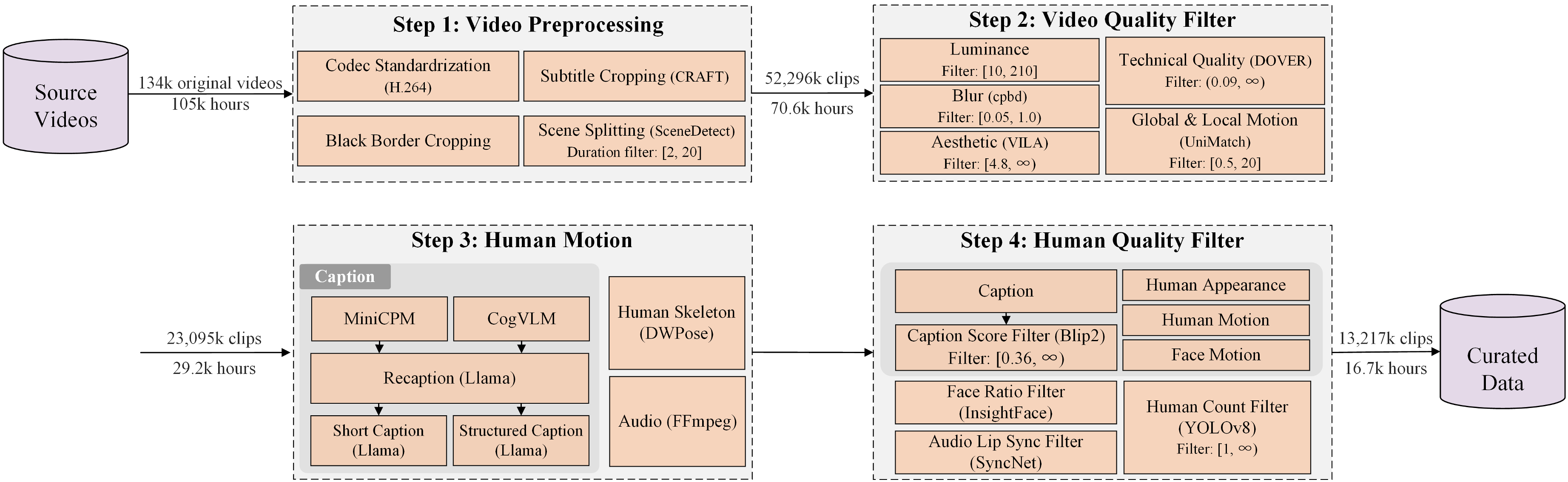
CVPR 2025 Highlight
A large-scale human-centric video dataset with precise captions and motion conditions, plus a filtering pipeline for improving video diffusion model training.

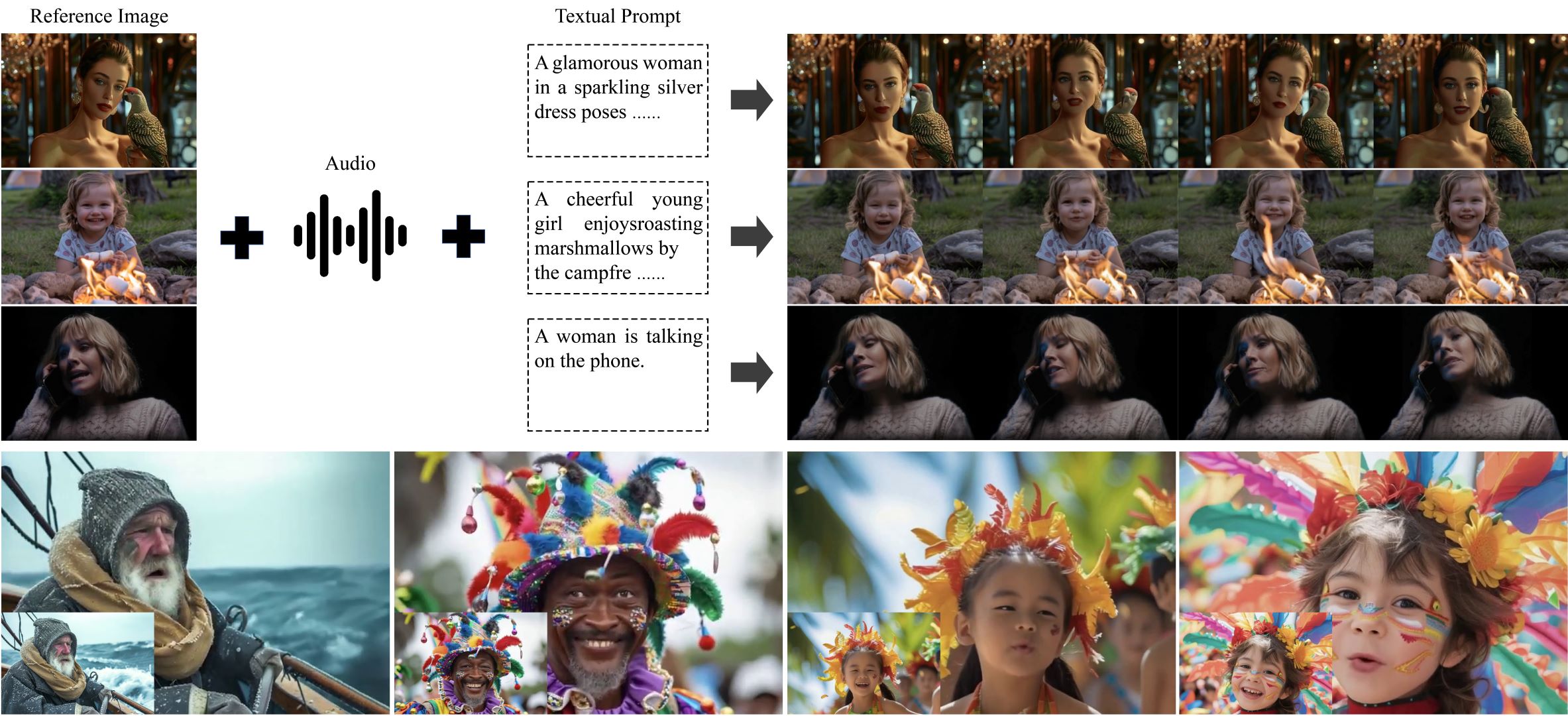
CVPR 2025
A portrait animation framework built on pretrained video diffusion transformers for more dynamic, realistic talking videos with natural backgrounds and motion.

ICLR 2025
A long-duration portrait animation system that extends audio-driven generation to high-resolution, temporally consistent videos.
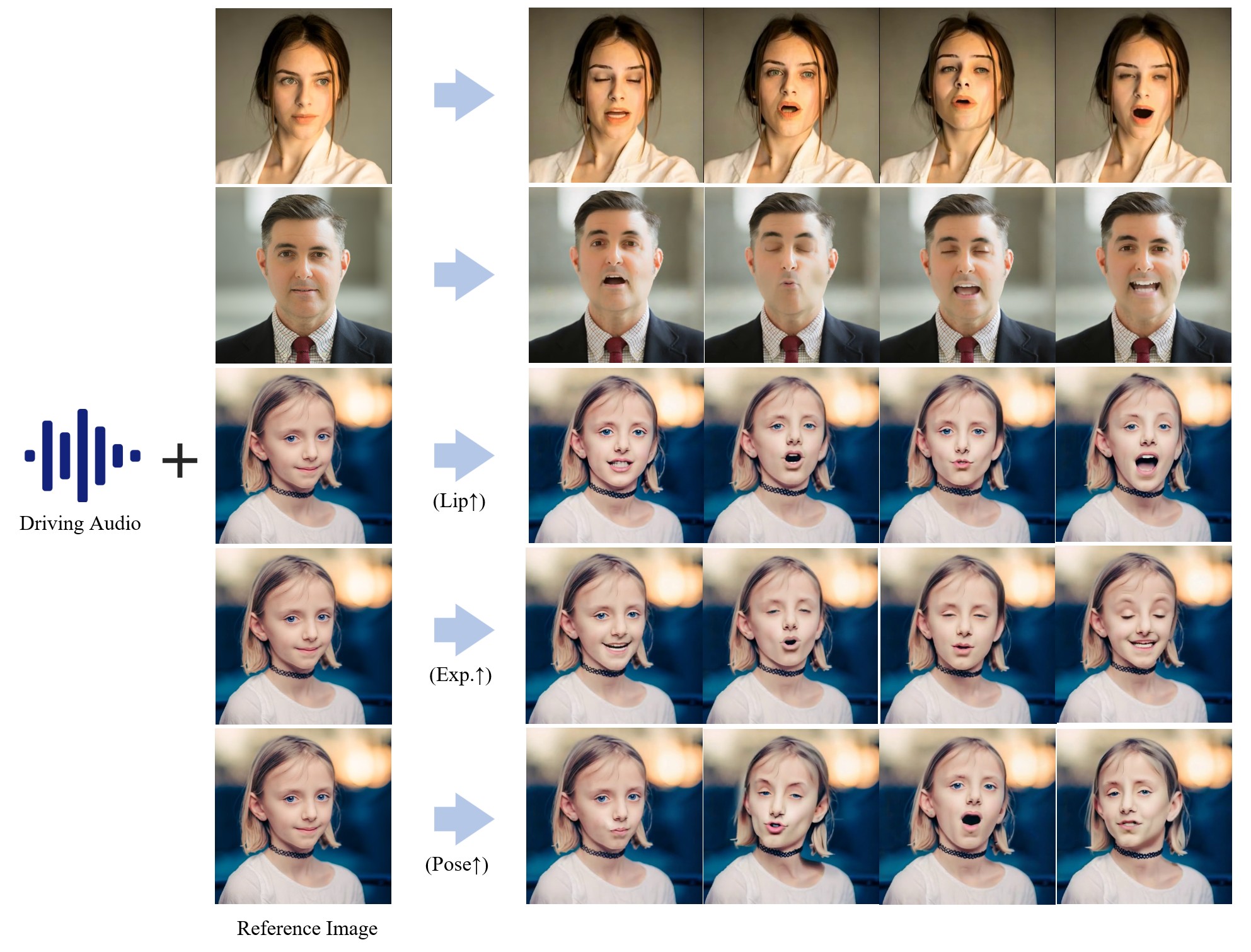
arXiv 2024
An open-source diffusion-based portrait animation framework with hierarchical audio-driven visual synthesis for lip, expression, and pose control.
Academic Service
Background
Ph.D. in Computer Science and Technology, School of Computer Science
M.S. in Mathematics, College of Artificial Intelligence
B.S. in Information and Computing Science, School of Mathematics
Algorithm Engineer. Worked on ControlGIF for image-to-video generation and video editing with AnimateDiff and ControlNet.